
추천시스템에 Deep Learning을 활용하는 이유
- Nonlinear Recommender System
- 한계점 : MF 모델은 선형조합에 기반한 표현만 가능
- -->> MLP 사용하여 비선형성 표현
- 한계점 : MF 모델은 선형조합에 기반한 표현만 가능

- Representation Learning
- DL은 사람이 직접 feature design을 하지 않아도 됨
- -->> 다양한 종류의 정보를 추천시스템에 활용할 수 있음
- DL은 사람이 직접 feature design을 하지 않아도 됨
- Flexibility
- 다양한 DL framework
- -->> 모델링이 자유로움
- 다양한 DL framework
1. NCF : Neural Collaborative Filtering
등장배경
MF의 한계 : MF는 선형조합에 기반한 표현만 가능 -> user-item의 복잡한 관계를 표현하는 것에 한계를 가지게 됨
NMF : Neural Matrix Factorization - NCF 논문의 최종모델
- 기존 MF 모델을 일반화한 GMF layer(Genealized MF layer) + NCF layer(MLP 사용한 model layer)

1-1) GMF layer
논문) 모델에서 나오는 예측값 y^과 비교할 값 y값은 아래와 같음

- 기존 MF는 pu와 qi의 element-wise하게 dot-product로 계산
- pu와 qi는 vector끼리의 내적으로 표현됨 (dot-product)

- GMF는 element 별로 곱한 값에 weight(h)를 곱하고 activation을 거쳐서 계산
- weight (h) : activation function & edgeweights of the output layer
- a_out : non-linear activation function -->> sigmoid
- h와 a_out을 항등함수로 사용하면 기존 MF와 같음

1-2) NCF layer
- Input layer : one-hot encoding된 user, item vector
- embedding layer : user, item latent vector
- neural CF layers

- output layer : user와 item 사이의 관련도

1-3) Ensemble
- 두 모델의 앙상블하는 간단한 방법은 embedding layer를 공유하고 output을 결합하는 것
- but, embedding을 공유하면 앙상블하는 의미가 없어짐 -> 융합모델의 성능 제한
- 논문에서는 융합모델에 flexibility를 보장하기 위해
- ::: GMF, NCF에서 각각 다른 embedding layer를 사용하여 별도로 학습 + 마지막 hidden layer를 concat
- pu_G, qi_G : GMF의 user, item latent vector
- pu_M, qi_M : NCF(MLP)의 user, item latent vector

1-4) Loss
Likelihood function

- interaction(Implicit feedback) 0,1에 대한 계산이며, y^은 0,1의 범위를 가짐
- Logistic이나 Porbit을 사용하여 확률적으로 접근
- Y : 관측된 집단 -> y = 1
- Y- : 관측되지 않은 집단 -> y = 0
Binary Cross-Entropy
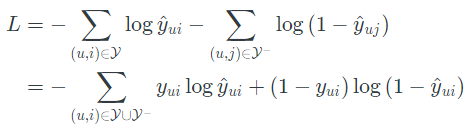
2. AutoRec
- 엄밀히 말하면 DL 모델은 아님
- Unsupervised 모델
AutoEncoder
- Encoder, Decoder 구조로 input을 축약했다가 다시 복원하는 과정을 통해 학습하는 방법
- input x에 대해 축약된 형태로 latent representation 할 수 있게 됨
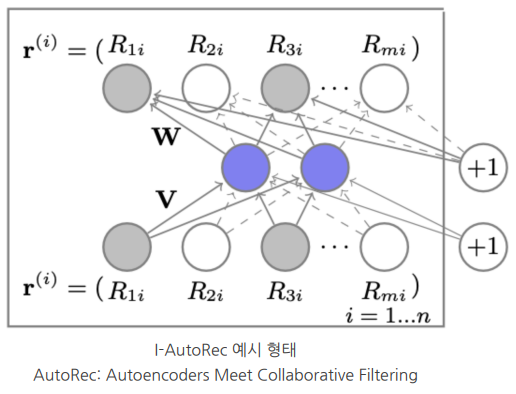
- User/Item vector를 저차원으로 embedding
- I-AutoRec : Item-based
- U-AutoRec : User-based
- encoder : g(x) -> linear()
- decoder : f(x) -> linear()
- h(r;θ) : reconstructed rating

- 관측 데이터만 대상으로 계산 후 정규화
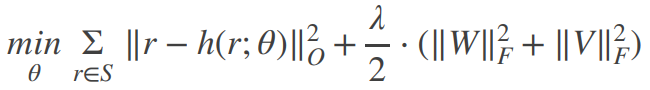
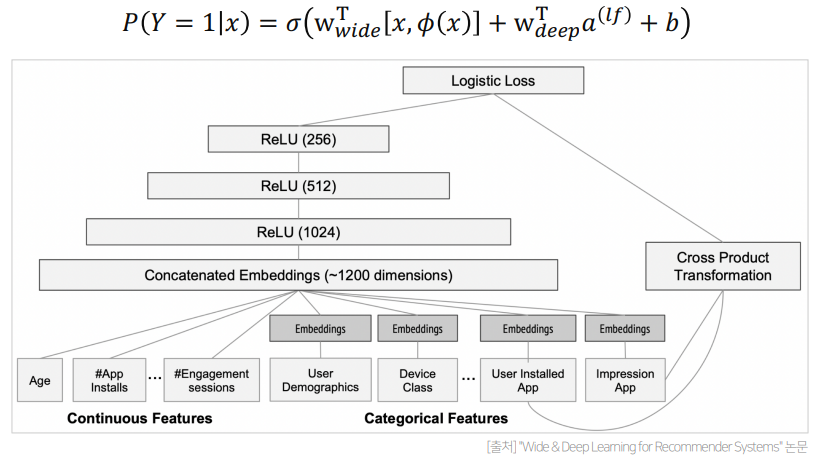
3. WDN : Wide Deep Network
추천시스템의 두 가지 chellenge - WDN의 접근법
1) Memorization : 암기 - 희소표현(Sparse Representation)
- Memorization
- 조합의 패턴을 그대로 암기
- 예시 : (남자, 컴퓨터) 조합에서 -> (남자가 컴퓨터를 클릭) 한 경우가 많다면 모델을 이 패턴을 그대로 암기
- 단순하고 확장 및 해석이 용이함
- but, 학습 데이터에 없는 데이터의 경우 예측 성능 떨어짐
- 조합의 패턴을 그대로 암기
- -> Sparse Representation
- Category Encoding layer : 범주형 변수를 one-hot encoding 처리 -> 희소표현
- 희소표현은 모델이 모든 변수 값들의 빈도를 학습 -> memorie하는데 도움
2) Generalization : 일반화 - 밀집표현(Dense Representation)
- Generalization
- 학습 데이터에 없거나 드물게 발생하는 경우도 적용가능하게끔 학습 -> 일반화
- FM이나 DNN 모델 같은 embedding으로 generalization 확보
- but, high-sparsity + high-dimensional한 데이터 -> 저차원의 embedding을 만들기 어려움
- -> Dense Representation
- Embedding layer : 범주형 변수를 저차원으로 embedding
- 밀집표현은 모델이 학습하지 못한 특징들의 조합을 상대적으로 잘 학습시킴 -> 일반화하는데 도움
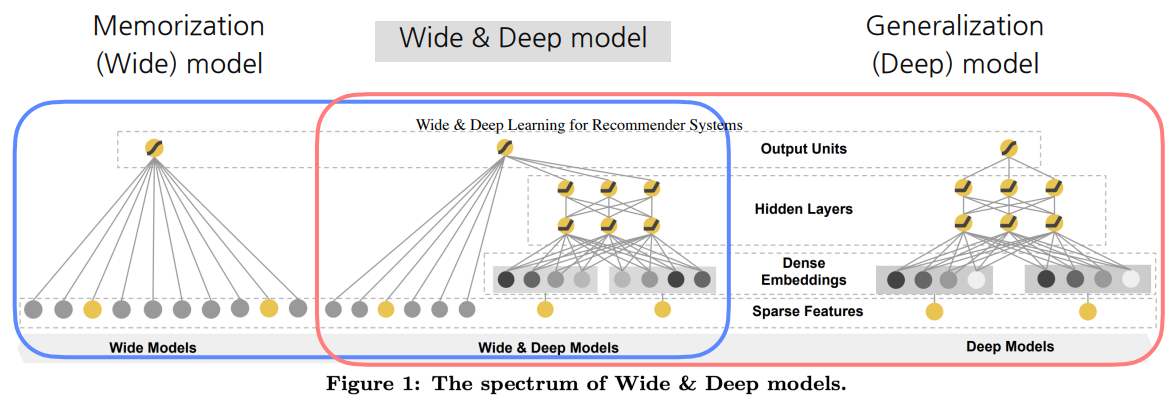
3-1) Wide Component
- Generalized Linear Model
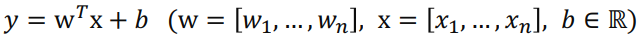
- Cross-Product Transformation
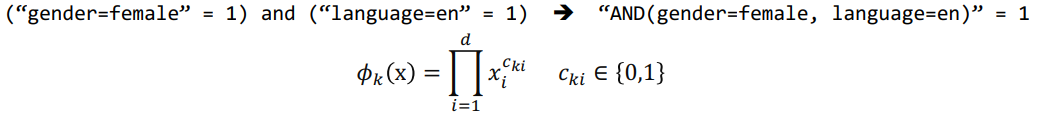
3-2) Deep Component
- Feed-Forward Neural Network
- Coninuous Feature는 그대로 사용 / Categorical Feature는 embedding해서 사용
- 전체구조 및 loss function
4. DCN : Deep Cross Network
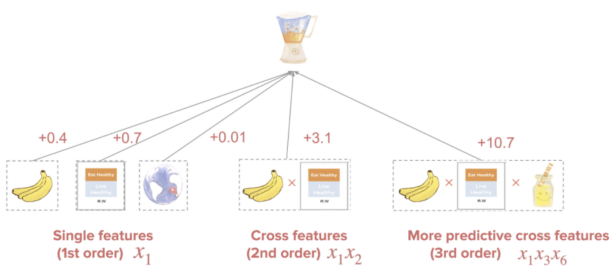
Feature 교차
핵심 : 여러 feature 간 특성이 같이 고려된 추천을 하는 것
특징 : DCN의 Cross Network에서 학습된 W를 통해 feature간의 interaction의 정도를 파악 가능(attention과 유사)
- ex) 믹서기를 추천할 것인가에 대한 모델에 [(바나나 - 요리책), ..., (요리책 - 지역)] 데이터보다
- [(바나나 - 요리책), ..., (요리책 - 지역)] 데이터가 더 중요한 정보를 제공
But,
- sparse하고 feature가 많은 데이터에서 -> feature 교차를 학습하는 것은 어려움
- DNN은 내부적으로 feature interaction은 상호작용을 학습할 수 있지만, 암시적으로 생성
- 모든 유형의 feature 교차를 학습할 때, 효과적이지 않을 수 있음
- Deep Cross Network에서, 특히 Cross Network Componect에서 명시적으로 feature 교차 적용
4-1) Cross Network
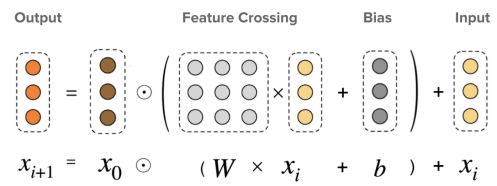
- i번째 x와 linear 계산 -> x0와 element wise product하는 구성 -> i+1번째 x 계산
- ::: Cross Network layer를 높게 쌓을 수록, Nth order cross를 반영하게 하는 효과가 있음
4-2) DCN V2 논문 - DCN Two Structures
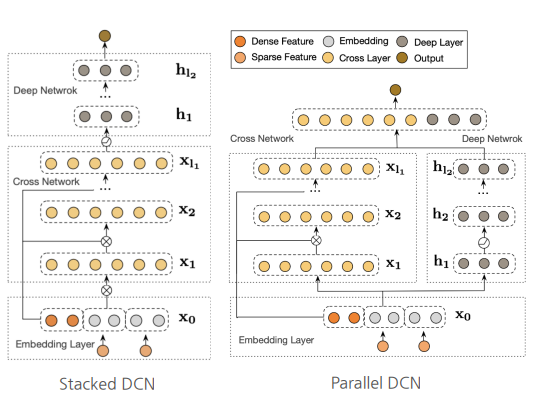
- Stacked DCN
- Cross layer를 통해 Explicit feature를 교차학습 -> Deep layer를 통해 Implicit feature를 교차학습
- Parrallel DCN
- Cross layer와 Deep layer 각각 feature를 교차학습 -> 두 layer의 마지막 output을 concat
-->> 데이터에 따라 성능이 좋은 구조가 다름
4-3) Low-Rank
- Production 레벨에서는 모델의 수용 능력이 모델 서빙 자원과 지연 속도 요건으로 인해 제한됨
- 제한된 수용 능력 하에서 정확도는 유지하면서, 비용을 감소시키기 위해 사용
ex) W(d x d)인 행렬 -> U, V (d x r)로 변경 ::: 학습 파라미터 수 감소 (r <= d/2)
::: 적은 학습 파라미터 == 적은 메모리 사용 & 빠른 학습 속도
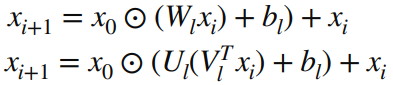
- W의 singular value가 빠르게 감소하면 효과가 좋음
- 실제로 production 레벨에 사용된 W가 빠르게 감소하는 것 확인
4-4) MoE : Mixture-of-Experts
: 여러 개의 Low-Rank 구조(Experts)를 만들어 결과를 예측하는 구조
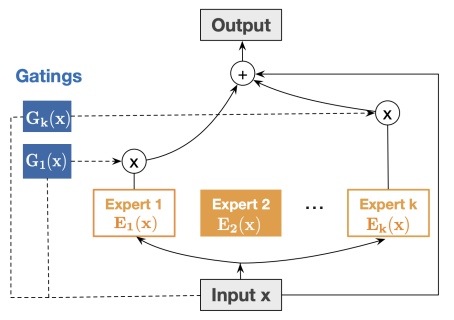
- Expert part : 작은 구조의 Low-Rank network
- Gate part : 입력된 데이터를 비선형 함수에 통과시켜 Expert에 가중치 부여
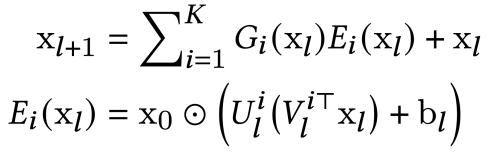
출처 : 부스트캠프 AI Tech 4기 강의자료, 구글링
'DS | Data Science > RecSys | Recommendation System' 카테고리의 다른 글
| [RecSys] 한 눈에 보기 정리 - 6 : Context-Aware Recommender System (0) | 2022.10.27 |
|---|---|
| [RecSys] 한 눈에 보기 정리 - 5 : Model-based Collaborative Filtering (0) | 2022.10.26 |
| [RecSys] 한 눈에 보기 정리 - 4 : Memory-based Collaborative Filtering (0) | 2022.10.26 |
| [RecSys] 한 눈에 보기 정리 - 3 : Content Based Recommendation System (0) | 2022.10.26 |
| [RecSys] 한 눈에 보기 정리 - 2 (0) | 2022.10.26 |