Model-based Collaborative Filtering이 필요한 이유
Memory-based CF의 문제점
- 희소 데이터 문제 : sparse data
- interaction의 수가 적음 -> 모델 성능 저하
- cold start가 어려워짐
- user interaction이 sparse matrix면, 유사도를 계산하기가 어려움 -> 유사도 행렬의 신뢰성 저하
- 확장성의 문제 : scalability
- 데이터가 많아질수록 연산량 증가
- 업데이트 될때마다(데이터 추가, 변경) 새로 user-item matrix를 연산해야함
- 실시간으로 연산하기에는 부적합
Model-based CF의 장점
- 데이터 패턴을 학습 -> 단순히 항목 간 유사성을 비교하는 것 X
- user-item 관계의 잠재적 특성 및 패턴을 찾을 수 있음
- user-item interaction 개수가 증가해도 좋은 성능
- 서빙 속도 향상
- sparse matrix의 경우, Matrix Factorization 등으로 해결 가능
Unsupervised VS Supervised
: 추천시스템에서는 딱 나눠지지 않으나 편의상 나누어서 정리함
1. Clustering Collaborative Filtering - Unsupervised Model

1) Clustring
: 가장 가까운 중심점을 갖는 군집에 각 항목을 할당하는 과정 반복 -> k개의 군집 형성
- 다양한 군집화 알고리즘
- k-Means
- DBCAN
- GMM(Gaussian Mixture Model)
- OPTICS
- Hierarchical Clustering
2) Collaborative Filtering
: 나눠진 군집 내에서 CF 실행 -> 추천
한계점
: 안그래도 sparse한 데이터를 군집해서 더 적은 양의 데이터를 사용 -> 실제환경에서 성능 저하
- K-Means : 구형 분포가 아닌 경우 군집화 성능저하 / 아웃라이어에 민감
- DBCAN : 차원 수가 커질수록 데이터 밀도가 떨어짐 -> 군집 형성의 어려움 ::: 차원의 저주
- GMM : 데이터가 정규성을 만족 X -> 성능 저하 // 계산량 많음
- Hierarchical Clustering : 모든 경우에 대해 반복적으로 유사도 계산 -> 계산량 많음
2. Unsupervised Learning Model - Latent Factor Model
Latent Factor Model
: 유저와 아이템 사이 다양한 정보를 담은 데이터를 축약된 벡터 공간에 표현할 수 있다는 아이디어
--> 축약 전에는 의미를 알 수 없던 값들이 축약 후에는 의미를 알 수 있게 됨
--> 벡터 공간에 표현된 유저와 아이템 중 가까운 위치에 있는 경우는 유사하다고 볼 수 있음
- 장점 : 저차원으로 매핑했을때 시각적으로 유사성 판단 가능
- 단점 : 각 잠재변수의 의미를 정확하게 알 수 없음
2-1) SVD : Singular Value Decomposition
- 목적
- latent factor matrix를 사용하여 user-item matrix의 비어있는 값(Implicit feedback)부분 유추
- 원래는 차원축소 용도로 많이 사용
- 행렬분해의 기본
- U(유저 잠재변수), Σ(diagonal matrix : 잠재변수), V(아이템 잠재변수) 세 개의 행렬의 곱으로 표현
- U(유저 잠재변수) : user와 latent factor의 관계
- Σ(diagonal matrix : 잠재변수) : latent factor의 중요도를 나타냄
- V(아이템 잠재변수) : item과 latent factor의 관계
주의점
- 차원 축소 시에 설정하는 k 값을 적절하게 조절해야함
- 너무 작게 설정하면 복원했을 때, 원래 있던 rating 데이터도 왜곡될 수 있음
한계점
- user와 item이 많아질수록 예측력 저하
- 결측치가 많은 데이터에 정상작동하기 어려움 -> 하지만 현실에서는 대부분 결측치
2-2) MF : Matrix Factorization
: User-Item Matrix(R)가 User Latent Factor(P)와 Item Latent Factor(Q) 2개의 행렬 곱으로 표현
- 목적
- 관측된 선호도(rating)만 모델링에 활용
- 관측되지 않은 선호도(rating)을 예측하는 일반화된 모델 생성
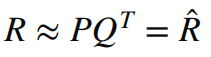
- R^이 R과 최대한 근사하도록 하는 문제
- 목적함수 ::: 최적화 문제로 정의됨

- overfitting 방지하기 위해 L2 regularization term 추가
- L2 regularization term은 학습되는 방향의 크기를 λ만큼 조절하게 됨
- 너무 많이 학습되지 않도록 하는 조치
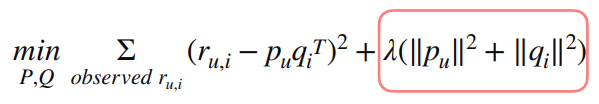
- 기존의 bias 정도를 반영하기 위해 bias term 추가

- 모든 평점이 동일한 신뢰도를 갖지 않음 -> rating에 대한 신뢰도(confidence) 추가 ::: 논문

- SGD 사용해서 학습 : mini-batch 사용해서 batch 내부에서 계산된 gradient로 업데이트 -> 연산속도 향상

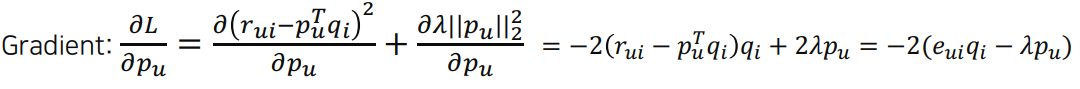
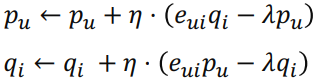
+ 추가)
MF for Implicit Feedback
Preference : user u가 item i를 선호하는지 여부 binary로 표현

Confidence : user u가 item i를 선호하는 정도를 나타내는 increasing function
* 알파는 positive feedback과 negative feedback 간의 상대적 중요도를 조정하는 hyper parameter
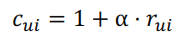
- 새로운 목적함수

한계점
: 계산 속도 문제
- 한번에 많은 계산
- p와 q를 동시에 처리해야 함 -> 한번에 계산해야 하는 양이 많음
- SGD가 매 mini-batch마다 적용되므로 계산량이 학습과정에서 누적됨
- 많은 연산량
- user, item 수가 증가하면 연산량 증가
2-3) ALS : Alternative Least Square
MF의 단점 : 연산량이 많아서 빠른 계산 X
-->> 대용량의 데이터를 병렬처리 함으로써 해결 가능
-->> p를 업데이트할땐 q를 상수취급해서 고정 -> p만 계산

- 한번에 많은 양의 계산 X -> 속도 향상
- element 단위 연산 X -> 행렬 단위 연산 가능 ::: 연산량 감소
업데이트 코드 구현시
- MF는 latent factor matrix를 만들어서 전체 user와 item에 대해 error 계산
- ALS를 적용한 MF는 latent factor마다 error 계산
- MF for Implicit Feedback에서 ALS 적용 시 latent factor

2-4) BPR : Baysian Personal Ranking
Personalized Ranking : 사용자에게 순서(Ranking)가 있는 아이템 목록을 제공하는 문제
예시) user u에 대해 item i > item j라면 user u의 Personalized Ranking
- 가정
- 관측된 아이템을 관측되지 않은 아이템보다 선호
- 관측된 아이템끼리 선호도 추론 가능
- 관측되지 않은 아이템끼리 선호도 추론 불가능
-->> 관측된 아이템과 관측되지 않은 아이템으로 ranking을 부여해서 학습
- 학습 데이터
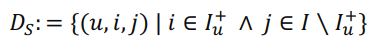
triple 데이터셋 : user u, item i, item j로 구성
- item i : 관측 O / 선호 +
- item j : 관측 X / 선호 ?
- MAP : Maximum A Posterior
Bayes 정리 사용 : Posterior를 최대화한다는 것 -> 주어진 유저 선호 정보를 최대한 잘 나타내는 파라미터(모수)를 찾는 것
- 목적함수

- LEARNBPR 사용하여 학습 : Bootstrap 기반의 SGD
- 일반적인 SGD 사용하면,
- 보통 i가 j보다 많아서 학습의 비대칭 발생
- 동일한 u, i에 대해 계속 업데이트 되므로 수렴 잘 안됨
2-5) Hybrid Approach
: 여러가지 추천방법을 사용(implement)
-->> cold start, sparsity 같은 문제들 해결 가능
예시
- Content-based + Collaborative Filtering
- Memory-based CF + Model Based CF
- Clustering + Memory-based CF
Hybridization 기술 종류
- Weighted : 서로 다른 추천의 점수를 가중 평균
- Switching : 사용하는 추천시스템을 변경하며 추천
- Mixed : 서로 다른 추천에서 나오는 추천들을 함께 섞어서 제공
- Feature Combination : 다른 추천에서 나온 특징들을 합쳐 하나의 추천 알고리즘에 사용
- Feature Augmentation : Feature Combination을 여러번 연결된 것
- Cascade : 엄격한 위계를 가진 추천으로 상위 우선순위 추천이 선행되어야 낮은 우선순위의 추천 가능
- Meta-level : 한 추천시스템 model이 입력으로 사용되는 model로 추천 / model 자체를 입력으로 전달
3. Supervised Learning Model
3-1) Naive Bayes
- 일반 Bayes 공식
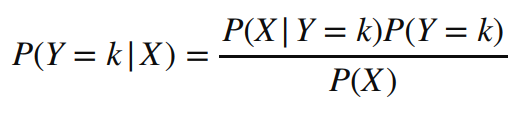
- 변수 X가 다변량인 경우
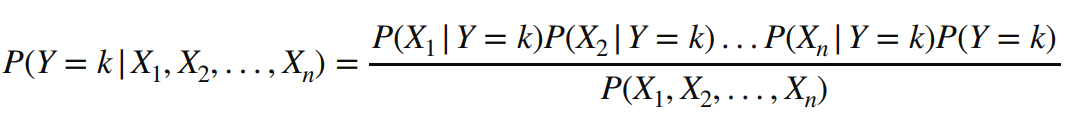
- 다변량 변수에서 서로 독립이라고 가정 -> Naive하다
- Chain Rule
- evidence
3-2) GBDT : Gradient Boosting Decision Tree

3-2-1) XGBoost
- Parallelization
- 병렬처리를 통해 속도 향상
- Level-wise
- 기존의 leaf-wise는 information gain이 있는 쪽에만 pruning
- depth 기준으로 level-wise pruning -> information gain이 없는 것도 추가적으로 분할 가능
- Regularization
- object function overfitting 방지
3-2-2) LightGBM
- Leaf-wise
- 속도 문제 때문에 다시 돌아옴 / 단, overfitting 위험
- GOSS(Gradient-based One-Side Sampling)
- Top N개 데이터 인스턴스와 랜덤 샘플링 데이터 인스턴스만 활용하는 GOSS 활용
- undersampling 되어서 데이터 인스턴스 수 감소
- EFB(Exclusive Feature Bundling)
- sparse한 feature가 많을 때 번들링 하는 EFB 사용
- 여러 feature를 하나의 feature인 것처럼 줄임 -> feature 수 감소
3-2-3) CatBoost
: Target Leakage 문제
- 예측 시점에서 사용할 수 없는 데이터가 뎅터 셋에 포함되어 있을 때 발생
- CatBoost에서는 모델 훈련에 사용하는 Boosting 훈련에 사용하는 데이터와 계산에 사용하는 데이터를 다르게 하는 것을 의미
- Level-wise
- Ordered Boosting
- n+1번째 order의 잔차 계산할때
- n번째까지 데이터로 학습한 모델에 x_n+1을 넣어 y_n+1과 비교하는 방식
- Ordered TS(Target Statistics)
- n+1번째 order의 Target Statistics를 계산할때
- n번째까지 데이터의 statistics 정보를 이용해 계산
유의점
- hyper parameter tuning이 GBDT의 핵심
'DS | Data Science > RecSys | Recommendation System' 카테고리의 다른 글
| [RecSys] 한 눈에 보기 정리 - 7 : Deep Learning (0) | 2022.10.27 |
|---|---|
| [RecSys] 한 눈에 보기 정리 - 6 : Context-Aware Recommender System (0) | 2022.10.27 |
| [RecSys] 한 눈에 보기 정리 - 4 : Memory-based Collaborative Filtering (0) | 2022.10.26 |
| [RecSys] 한 눈에 보기 정리 - 3 : Content Based Recommendation System (0) | 2022.10.26 |
| [RecSys] 한 눈에 보기 정리 - 2 (0) | 2022.10.26 |