728x90
반응형
인기도 기반 추천 / 평가지표
- MovieLens 데이터셋 가공
- 가공한 데이터 활용 -> 인기도 기반 추천
- 평가지표
1. 전처리
- MovieLens 100k Dataset
- 원천데이터
https://grouplens.org/datasets/movielens/
MovieLens
GroupLens Research has collected and made available rating data sets from the MovieLens web site ( The data sets were collected over various periods of time, depending on the size of the set. …
grouplens.org
- 데이터 구성
- 영화에 대한 제목, 장르, 연도 등의 데이터
- 유저에 대한 성별, 연령, 직업, 주소 등의 데이터
- Explicit Feedback : 유저가 아이템에 대한 선호도 1.0~5.0
# 사용 columns
ratings_df.columns = ['user_id', 'movie_id', 'rating', 'timestamp']
movies_df.columns = ['movie_id', 'movie_title', 'release_date', 'video_release_date',
'IMDb_URL', 'unknown', 'Action', 'Adventure', 'Animation',
'Children', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy',
'Film-Noir', 'Horror', 'Musical', 'Mystery', 'Romance', 'Sci-Fi',
'Thriller', 'War', 'Western']
users_df.columns = ['user_id', 'age', 'gender', 'occupation', 'zip_code']
- 평점 데이터의 기초 통계량
n_user = len(ratings_df['user_id'].unique())
n_movie = len(ratings_df['movie_id'].unique())
print('사용자 수:', n_user, ', 영화 수:', n_movie)사용자 수: 943 , 영화 수: 1682
ratings_df[['user_id', 'movie_id', 'rating']].describe() user_id movie_id rating
count 100000.00000 100000.000000 100000.000000
mean 462.48475 425.530130 3.529860
std 266.61442 330.798356 1.125674
min 1.00000 1.000000 1.000000
25% 254.00000 175.000000 3.000000
50% 447.00000 322.000000 4.000000
75% 682.00000 631.000000 4.000000
max 943.00000 1682.000000 5.000000
sns.displot(ratings_df['rating'])
plt.show()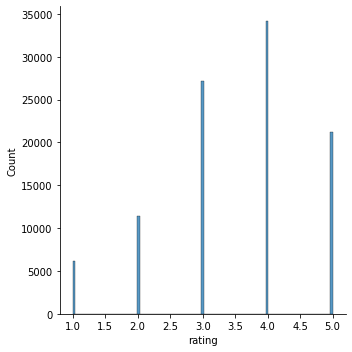
- aggregated_df : 평점 정보를 저장하고 있는 ratings_df를 aggregate하여 'movie', 'user'별로 'num_users(num_rating)', 'avg_rating', 'std_rating'으로 groupby
- get_top_k : 앞서 계산한 aggregated_df를 사용하여 상위 k개의 아이템을 출력
- get_stream_rating : 각 영화별 'stream_rating'을 계산하여 df에 추가
- 영화 기준 aggregated_df
movie_statistics = aggregate(ratings_df, ['movie_id'], 'movie')
movie_statistics.head() movie_id num_users avg_rating std_rating
0 1 452 3.878319 0.927897
1 2 131 3.206107 0.966497
2 3 90 3.033333 1.212760
3 4 209 3.550239 0.965069
4 5 86 3.302326 0.946446
- user 기준 top k개 영화
get_top_k(movie_statistics, 'num_users', 10, 'movie_id') movie_id num_users avg_rating std_rating
49 50 583 4.358491 0.881341
257 258 509 3.803536 0.994427
99 100 508 4.155512 0.975756
180 181 507 4.007890 0.923955
293 294 485 3.156701 1.098544
285 286 481 3.656965 1.169401
287 288 478 3.441423 1.113910
0 1 452 3.878319 0.927897
299 300 431 3.631090 0.998072
120 121 429 3.438228 1.116584
- 평균 평점이 가장 높은 영화 k개
get_top_k(movie_statistics, 'avg_rating', 10, 'movie_id') movie_id num_users avg_rating std_rating
813 814 1 5.0 NaN
1598 1599 1 5.0 NaN
1200 1201 1 5.0 NaN
1121 1122 1 5.0 NaN
1652 1653 1 5.0 NaN
1292 1293 3 5.0 0.0
1499 1500 2 5.0 0.0
1188 1189 3 5.0 0.0
1535 1536 1 5.0 NaN
1466 1467 2 5.0 0.0
- Streaming Rating이 높은 k개 영화
get_steam_rating(movie_statistics)
get_top_k(movie_statistics, 'steam_rating', 10, 'movie_id') movie_id num_users avg_rating std_rating steam_rating
317 318 298 4.466443 0.829109 4.112553
63 64 283 4.445230 0.767008 4.089672
49 50 583 4.358491 0.881341 4.085208
482 483 243 4.456790 0.728114 4.082330
11 12 267 4.385768 0.825500 4.034987
407 408 112 4.491071 0.771047 4.009999
602 603 209 4.387560 0.712551 4.009581
168 169 118 4.466102 0.823607 3.998466
97 98 390 4.289744 0.836597 3.992712
126 127 413 4.283293 0.934577 3.992393
2. Top K recommendation 평가지표
- Precision@K / Recall@K / MAP@K
- Precision@K
- 추천한 K개 아이템 중, 실제 사용자가 관심 있는 아이템의 비율
- Recall@K
- 사용자가 관심 있는 전체 아이템 중, 추천한 아이템의 비율
- AP@K
- Precision@1부터 Precision@K까지의 평균값
- 관련 아이템을 더 높은 순위에 추천할수록 점수가 상승

- MAP@K
- 모든 유저에 대한 Average Precision 값의 평균
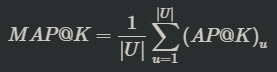
- NDCG @ K
- 추천 시스템에 가장 많이 사용되는 지표
- 검색(Information Retrieval)에서 등장한 지표
- Top K 리스트를 만들고 유저가 선호하는 아이템을 비교하여 값을 구함
- 순서에 가중치를 더 많이 두어 성능을 평가하여 1에 가까울수록 좋음
- 연관성을 이진(binary)값이 아닌 수치(1.0~5.0)로도 사용할 수 있음
- 사용자에게 얼마나 더 관련 있는 아이템을 상위로 노출시키는지 알 수 있음
- Cumulative Gain : CG
- 상위 K개 아이템에 대하여 관련도(relevant)를 합한 것
- 순서에 따라 Discount하지 않고 동일하게 더한 값
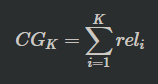
- Discounted Cumulative Gain : DCG
- 순서에 따라 Cumulative Gain을 Discount함

- Ideal DCG
- 이상적인 추천이 일어났을 떄의 DCG 값
- 가능한 DCG 값 중에 가장 큼

- 유저의 relevant item 개수가 k보다 적을 경우가 존재함
- 1) k = 5, 유저의 relevant item 개수가 5개 이상이라면 idcg = (1/log2) + (1/log3) + (1/log4) + (1/log5) + (1/log6)
- 2) k = 5, 유저의 relevant item 개수가 3개라면 idcg = (1/log2) + (1/log3) + (1/log4)
- Normalized DCG
- 추천 결과에 따라 구해진 DCG를 IDCG로 나눈 값
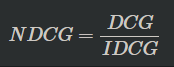
참고자료 및 출처 : 네이버커넥트 부스트캠프 AI_Tech 강의자료, https://grouplens.org/datasets/movielens/
728x90
반응형
'DS | Data Science > RecSys | Recommendation System' 카테고리의 다른 글
| [RecSys] 한 눈에 보기 정리 - 2 (0) | 2022.10.26 |
|---|---|
| [RecSys] 한 눈에 보기 정리 - 1 (0) | 2022.10.20 |
| [RecSys] kNN Collaborative Filtering : scikit-surprise 라이브러리 / MovieLens Data (0) | 2022.10.14 |
| [RecSys] Basic - 2 (0) | 2022.10.11 |
| [RecSys] Basic - 1 (0) | 2022.10.10 |