기존의 추천시스템은 두 가지 방법론이 주류를 이룬다.
1) Content Based Approach
2) Collaborative Filtering
Content Based Approach은 영화를 추천할 때 우선 영화를 장르에 따라 분류하고, 특정 장르를 좋아하는 사람에게 해당 장르의 영화를 추천해주는 방식이다. 하지만 이 방식은 각각의 Content (영화 등)의 profile(장르, 배우 등의 속성)을 구성하는 전단계가 필요하고 Overspecialization, 유저의 Content Profile을 벗어나는 추천을 하기 어렵다. 그렇기 때문에 분류된 장르에 대해서만 추천이 가능하므로 유저에게 새로운 장르를 추천하거나 하는 등의 행동으로 이어지지는 않게 된다는 문제점이 있다.
Collaborative Filtering는 따로 profile 구성이 없이 유저와 비슷한 취향을 가진 다른 유저의 영화 목록을 추천해주는 방식이다. Content based approach 보다는 specialization이 비교적 넓게 적용될 수 있다는 장점이 있지만, 다른 영화 목록이라는 데이터 집단이 필요하기 때문에 초기에 데이터가 부족한 경우에서는 Cold Start가 힘들다는 문제점이 있다.
이 논문은 Collaborative Filtering에 관한 내용이다.
그러나 Implicit Feedback Dataset을 활용한다는 점이 이 논문의 차별점이자 쟁점이다.
- Implicit Feedback vs Explicit Feedback
- Explicit Feedback : 그 사람이 해당 영화를 어떻게 평가했는지를 직접적으로 알 수 있는 경우
- Implicit Feedback : 그 사람이 해당 영화를 어떻게 평가했는지를 간접적으로 알 수 있는 경우
넷플릭스나 디즈니플러스와 같은 OTT서비스에서는 영화에 대한 평점을 매길 수 있다. 이것은 유저가 직접적으로 해당 영화에 대한 선호도를 표시하는 것으로 이를 Explicit Feedback이라고 한다.
하지만, 실제로 직접적으로 평가를 하는 사람의 수는 생각보다 적다. 개인적인 상황에 비추어 보면, OTT 서비스에서 보고싶어서 보는 영화에 대해서도 그저 시청하기만 하는 경우가 많았다. 또, 딱히 보고싶어서 본다기보다 마음에 드는 영화가 없어서 혹은 못찾아서 적당히 골라 틀어놓는 경우도 있었다.
이럴 경우 얻을 수 있는 정보는 해당 유저가 영화를 얼마나 시청했는지, 어떤 영화를 시청했는지 등에 대한 정보만을 얻을 수 있는데 이를 통해서 선호도나 호감이 있다고 판단할 수 있을지는 모른다. 하지만 다른 정보들에서 유추하여 선호도를 평가하는 것은 가능할지도 모른다.즉, 명시적으로 표시되지는 않았지만 간접적으로 유추가 가능한 피드백을 Implicit Feedback이라고 한다.
논문에서는 Implicit Feedback Dataset의 특징은 다음과 같다.
- 호감에 대해서는 알 수 있지만, 불호에 대해서는 알 수 없다.
- 호감 중에서도 확실한 호감을 알기가 어렵다.
- 숫자의 크기가 선호도가 아닌 신뢰성에 가깝다. 많이 시청한 드라마라고 해서 그걸 좋아하기 보다는 오랜 기간 방영한 드라마이여서 그럴수도 있다는 것.
- 적절한 평가지표가 필요하다. Explicit의 경우에는 예측값과 실제값을 단순히 비교해도 되지만 Implicit은 실제값을 정해주는게 중요하다.
본문
기존의 Collaborative Filtering의 메서드
1) Neighborhood Model

Neighborhood Model은 user(u)가 item(i)에 대한 평가 (예를 들면 평점 : r (rating)) r_ui를 통해 만들어진다. i가 아닌 다른 item j에 대해서 평가한 데이터 r_uj를 Sij와 가중평균을 한다. Sij는 item i와 j가 얼마나 비슷한 속성을 나타내는 값으로 보통 피어슨 상관계수로 계산한 similarity이다. 즉, 예측된 값 r^_ui는 주변 neighborhood item(i를 제외한 item)들의 가중평균이다.
2) Latent Factor Model

Latent Factor Model에서는 Item과 User의 상관관계가 Item latent vector와 User latent vector의 행렬 분해로 설명할 수 있다고 생각한다. x_u는 user(u)에 대한 latent vector이고, y_i는 item(i)에 대한 latent vector이며 이 둘을 내적하고 이 결과가 r_ui가 되도록 학습한다. 오른쪽의 λ가 있는 term은 정규화를 하기 위한 것이다.
논문의 핵심 내용은 위의 Latent Factor Model에서 r_ui를 바로 쓰지 않고 전개했다는 점이다.


논문의 loss function에서의 특징은 latent factor model에서 사용하던 r_ui를 p_ui로 대체했다는 것이다. p_ui는 r_ui가 0보다 클때 1, 작을때 0이라는 값을 가지는 binary 값이다. 또, 새로 c_ui라는 값을 만들어서 r_ui의 값에 비례하게 만들어 커질수록 높은 신뢰도를 가진다는 의미로 loss function에 가중치로 사용한다.
p_ui는 해당 user가 해당 item을 사용했다면 1 아니면 0, c_ui는 user가 item을 선호도랑 상관없이 사용한 것을 처리하기 위함이라고 한다.
또한,
r_ui의 최소값을 0이 아닌 값으로 설정하여 c_ui를 log scale로 유도할 수도 있다.

또, 논문에서는
실제 구현시에는 X와 Y 각각의 latent vector를 학습하는데 있어서 Alternative Least Square(ALS)라는 방식을 사용한다. 이 방식의 핵심은 X를 학습할 때 Y를 상수 취급하고, Y를 학습할 때 X를 상수 취급하는 식으로 학습하는 것으로, 학습의 효율적인 측면과 학습을 설명가능하게 한다는 장점이기도 하다고 밝혔다.
* SGD를 사용해서 학습할 수도 있지만, 데이터가 매우 커지기 때문에 사용하지 않았다고 함. x_u를 업데이트하는 데에 있어서 다른 변수와 연관성이 없기 때문에 x_u와 y_i를 따로 계산이 가능하다고 함.
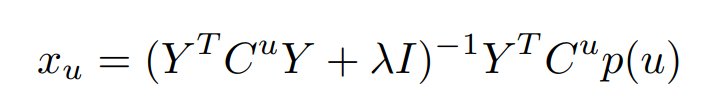

user(u)의 item(i)에 대한 선호도는 X_u와 Y_i의 내적으로 표현되며, 예측값 p^_ui는 y_i.T*x_u으로 표현된다. 여기서 x_u를 위의 식으로 치환하고 중간 부분의 (Y.T*C^u*Y + λI)^-1을 Wu로 치환하면, user(u)에 대한 가중행렬로 볼수 있다. 그러므로 user(u)를 기준으로 하여 item(i)와 item(j) 사이의 weighted similarity는 아래와 같다.

이는 Neighborhood model과 유사하게 이해할 수 있겠다.
결과

평가 수식은 위와 같은 rank라는 측도를 사용한다. 0에 가까울 수록 item(i)는 잘 추천된 것이 되며, 100에 가까울수록 잘 추천하지 못한 것이 된다.
* 실험 모델
1. Popularity : User에 관계없이 가장 인기있는 프로그램을 추천하는 모델.
2. Neighborhood: Item-based neighborhood model
3. Factor : latent vector의 크기를 다르게 하면서 학습한 본 논문의 모델들.
위의 세 가지 모델에 대한 rank 결과값을 도식화하면 아래와 같다.

3번 Factor 모델이 가장 좋은 성능을 보였고, factor를 키울수록 증가하다가 어느정도 정체되는 구간이 발생했다.
정리 요약
Content Based Approach
- 영화 추천의 경우, 영화를 장르에 따라 분류하고, 특정 장르를 좋아하는 사람에게 해당 장르의 영화를 추천해주는 방식
- 단점 : 각각의 Content (영화 등)의 profile(장르, 배우 등의 속성)을 구성하는 전단계가 필요하고 Overspecialization, 유저의 Content Profile을 벗어나는 추천을 하기 어려움
Collaborative Filtering
- 따로 profile 구성이 없이 유저와 비슷한 취향을 가진 다른 유저의 영화 목록을 추천해주는 방식
- 단점 : 다른 영화 목록이라는 데이터 집단이 필요하기 때문에 초기에 데이터가 부족한 경우에서는 Cold Start가 어려움
Implicit Feedback vs Explicit Feedback
- Explicit Feedback : 그 사람이 해당 영화를 어떻게 평가했는지를 직접적으로 알 수 있는 경우
- Implicit Feedback : 그 사람이 해당 영화를 어떻게 평가했는지를 간접적으로 알 수 있는 경우
Implicit Feedback Dataset 특징
- 호감에 대해서는 알 수 있지만, 불호에 대해서는 알 수 없다.
- 호감 중에서도 확실한 호감을 알기가 어렵다.
- 숫자의 크기가 선호도가 아닌 신뢰성에 가깝다. 많이 시청한 드라마라고 해서 그걸 좋아하기 보다는 오랜 기간 방영한 드라마이여서 그럴수도 있다는 것.
- 적절한 평가지표가 필요하다. Explicit의 경우에는 예측값과 실제값을 단순히 비교해도 되지만 Implicit은 실제값을 정해주는게 중요하다.
내용
기존의 Collaborative Filtering 메서드
1) Neighborhood Model
2) Latent Factor Model
중에서 Latent Factor Model을 변형해서 사용한다. 선호도가 표시되지 않은 user의 선호도를 평가하는 척도로써 새롭게 c_ui를 사용하였고, 이것과 r_ui를 사용하여 선호도를 평가하는 방식이다.
실제 구현에서 r_ui가 0보다 작아지는 것까지 포함시키기 위해 c_ui를 log scale로 변환하고 Alternative Least Square(ALS)를 사용하여 아이템 간의 weighted similarity을 계산하여 p_ui를 계산하여 loss를 업데이트한다.
결과적으로 Implicit Feedback을 loss에 적용시킬 수 있어서 모델 성능이 향상된 것을 볼 수 있다.