
1. Optimization의 중요성
Optimiaztion(최적화)는 머신러닝 관점에서 몇 가지 논점에서 바라 볼 수 있다.
1) 일반화 (Generalization)
2) 과대적합 vs 과소적합 (Ovefitting vs Underfitting)
3) 교차검증 (Cross Validation)
4) 편향-분산 트레이드오프 (Bias-Variance Tradeoff)
5) 부트스트래핑 (Bootstrapping)
6) 배깅과 부스팅 (Bagginf and Boosting)
1-1) 일반화 (Generalization)
Generalization라고 하면 일반적으로 train error는 학습과정에서 계속해서 작아짐에 따라, test error도 줄어들었을 때 학습이 잘 되었으며, Generalization가 잘 되었다고 할 수 있다. 이때, train error와 test error의 차이를 Generalization gap이라 하며 일반적으로 iteration이 진행될 수록 train error는 계속해서 감소해서 수렴하는 양상을 보일 수 있지만, test error는 어느 지점에서 역으로 상승하는 경향을 보일 수 있다.
1-2) 과대적합 vs 과소적합 (Ovefitting vs Underfitting)
위의 Generalization 문제에서 보면 train error는 iteration이 진행되면서 계속해서 줄어드는 것을 확인할 수 있다. 이때 문제가 될 수 있는 점이 test 데이터는 절대로 학습과정에 사용하면 안된다는 점인데, 만약 학습과정 중에 test 데이터를 사용해서 학습을 하게 되면 나중에 test step에서 과적합(overfitting)과 같은 결과를 볼 수 있게 된다.
쉬운 예시를 하나 들면, 수능을 준비하기 위해서 모의고사를 풀어야하는데 수능 시험 문제와 답을 빼돌려서 그 답을 외우고 수능을 응시하게 되는 것과 마찬가지가 된다. 이 경우, 수능에서는 만점을 받을 수는 있지만 기본적인 학습이 되지 않았기에 다른 문제에서는 0점이 나올 수 있는 것이다. 이처럼 train 데이터에만 정확하게 학습되는 현상을 과대적합(overfitting)이라고 한다.
반대로 과소적합(Underfitting)은 학습데이터를 너무 무시하여 naive하게 학습되는 것 혹은 학습이 안된 상태를 말한다. 주로 loss 값을 업데이트가 잘 안되었거나 gradient 계산이 잘못되었을 때 볼 수 있다.
1-3) 교차검증 (Cross Validation)
교차검증은 모델을 일반화하기 위해서 사용하는 방법중 하나로 train data를 일정비율(k)로 나누어서 validation 데이터셋으로 사용하는 것을 말한다. 주로 학습이 진행되는 양상을 보며 모델 수정이나 Hyper parameter Tuning을 하기 위한 척도로 사용하기 위해 학습 진행상황을 체크하거나 Generalization gap을 확인하기 위한 방법으로 사용된다.
이때 일정부분을 validation 데이터셋으로 사용한 데이터셋을 학습에 활용하기 위해서 위 이미지와 같이 split을 여러번 돌게 하는 방법을 K-fold Validation이라고 한다. 위 이미지는 5개의 fold로 validation을 5번 진행하게 된다.
Cross-Validation을 함으로써 학습에 있어서 치우침이 없게 학습할 수 있기 때문에 최적화의 방법 중 하나로 사용하게 된다.
1-4) 편향-분산 트레이드오프 (Bias-Variance Tradeoff)
Bias는 편향성, Variance는 분산이다. Bias는 내가 목표로 하는 지점에서 데이터가 치우친 정도를 말하고, Variance는 데이터들의 분산을 말한다.
위의 이미지와 마찬가지로 Bias가 높으면 중심에서 한쪽으로 값이 치우치게 되고, Variance가 높으면 데이터의 분포가 퍼져있게 된다.
cost function은 위와 같이 bias와 variance, noise로 나누어 볼 수 있다. 이때 noise는 불가피한 error부분이 된다.
모델이 복잡해질 수록 bias는 작아지고, variance는 커지게 되어 overfitting된다. 또, 모델이 단순해질수록 bias는 커지고, variance은 작아지게 되어 underfitting 된다. bias와 variance 중 한쪽만 줄이거나 키우는 것으로 모델을 최적화할 수는 없기 때문에, 오류를 최소화하려면 bias와 variance를 종합적으로 고려해야한다.
즉, Bias-Variance Tradeoff는 이러한 bias와 variance의 합을 최소화하는 값으로 모델을 최적화하는 문제가 된다.
1-5) 부트스트래핑 (Bootstrapping)
Bootstrapping은 부츠 끈을 양쪽을 번갈아서 당기며 줄을 매는 것과 같이 표본데이터에서 여러번 샘플을 뽑아서 모수를 추정하는 방법이다. 데이터 불균형의 문제를 해결하는 방법으로, 이론적으로 표본집단은 모수에서 뽑은 표본이기 때문에 여기에서 다시 표본을 뽑아 근사하면 원래의 모수를 추정할 수 있다는 아이디어이다.
1-6) 배깅과 부스팅 (Bagginf and Boosting)
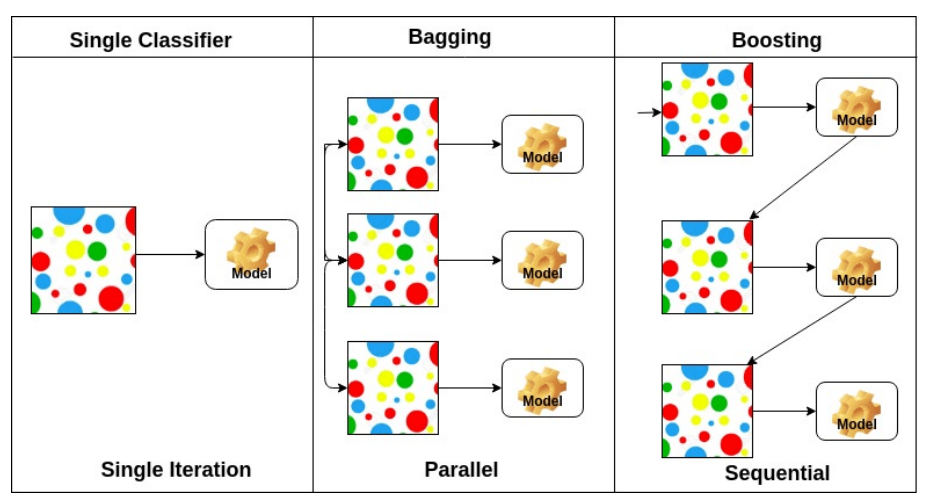
Bagging은 Bootstrapping aggregation의 약자로 Bootstrapping에서처럼 여러개의 데이터 집합을 통해 각각의 모델(multiple subset model)을 학습한 후 그렇게 만들어진 모델들을 독립적으로 취급하여 각각의 출력값을 평균 등으로 취합하고 학습하는 것을 말한다.
Boosting은 bagging과 유사하게 나누어진 데이터 집합에서 모델을 학습하지만 그 모델을 독립적으로 학습시키는 것이 아니라 한 모델에서 학습된 parameter들을 순차적으로 연결하여 다음 모델에서 이어서 학습하게 된다. 즉, 여러개의 모델들을 sequential하게 학습하여 마지막의 strong model을 만드는 것이 된다.
위의 방법은 한 개의 모델을 학습하는 것에 있어서 결과값을 더 general하게 학습할 수 있도록 최적화하는 방법으로
Ensemble이라고도 한다.
이미지 출처 : 네이버커넥트 부스트캠프 AI Tech 강의자료, 구글링 등
'DS | Data Science > ML | Machine Learning' 카테고리의 다른 글
| [DL Basic] Optimization 최적화 - 3 : Regularization (0) | 2022.10.04 |
|---|---|
| [DL Basic] Optimization 최적화 - 2 : Gradient Descent (0) | 2022.10.04 |
| [ML] Transfer Learning and Hyper Parameter Tuning (1) | 2022.09.29 |
| [Pytorch] hook & apply (0) | 2022.09.28 |
| [Gradient] Autograd - .backward(gradient = external_grad) (0) | 2022.09.28 |